데이터 모델은 소프트웨어 개발에서 가장 중요한 부분이다. SW가 어떻게 작성됐는지 뿐만 아니라 해결하려는 문제를 어떻게 생각해야 하는지 영향을 미치기 때문이다.
대부분의 애플리케이션은 하나의 데이터 모델을 다른 데이터 모델 위에 계층을 둬서 만든다.
2장에서 중요한 내용 - 범용 데이터 모델 비교(관계형 모델, 문서 모델, 그래프 기반 데이터 모델) - 여러 질의 언어와 사용 사례
관계형 모델과 문서 모델
가장 잘 알려진 데이터 모델은 1970년 에드가 코드가 제안한 관계형 모델으로한 SQL이다. 관계(relation)(=테이블)로 구성 되고 튜플(tuple)(=로우)의 모임.
관계형 데이터베이스의 근원은 비즈니스 데이터 처리에 있다. -> 트랜잭션 처리, 일괄 처리 관계형 모델의 목표는 정리된 인터페이스 뒤로 구현 세부 사항을 숨기는 것이다.
NoSQL의 탄생
NoSQL은 약 30년간 지속된 관계형 모델의 우위를 뒤집으려는 가장 최신의 시도이며 NoSQL은 어떤 기술이 아닌 Not Only SQL로 해석됨. NoSQL 데이터베이스를 채택하게 된 원동력 - 대규모 데이터셋이나 많은 처리량 달성을 쉽게 하기 위한 확장성 필요 - 무료 오픈소스 소프트웨어 선호도 증가 - 관계형 모델에서 지원하지 않는 특수 질의 - 관계형 스키마에 제한에 따르지 않는 모델
객체 관계형 불일치
객체지향 프로그래밍 언어 애플리케이션에서 데이터를 관계형 테이블에 저장하려면 둘 사이에 전환 계층 필요 -> 임피던스 불일치(impedance mismatch)
모든 내용을 갖추고 있는 데이터 구조는 문서이기 때문에 JSON표현에 적합하다. -> 문서 지향 데이터베이스(document-oriented)
다대일과 다대다 관계
중복된 데이터를 정규화하려면 다대일 관계를 사용한다.(문서 모델과 적합하지 않음 -> 조인 지원 약함) 애플리케이션의 데이터는 개발되면서 상호 연결되는 경향이 있다.(다대일, 다대다 필요성)
과거 IBM의 데이터모델 IMS의 설계는 계층 모델 사용
문서 데이터베이스 JSON 모델과 유사했다. 다대다 관계 표현의 문제를 해결하기 위한 해결책 두가지는 관계형 모델(SQL)과 네트워크 모델이었다.
네트워크 모델(=코다실 모델)
계층 모델을 일반화 하며, 계층 모델 트리 구조에서 모든 레코드는 하나의 부모가 있지만 네트워크 모델에서는 다중 부모가 있을 수 있다. 접근 경로는 최상위 레코드에서부터 연속된 연결 경로를 따르는 방법. 문제는 다른 경로가 같은 레코드로 이어질 수 있고 프로그래머가 경로의 맨 앞에서 접근 경로를 계속 추적해야함.
관계형 모델(SQL)
관계형 모델이 하는 일은 알려진 모든 데이터를 배치하는 것이다. 튜플(로우) 컬렉션이 전부이며 복잡한 접근 경로가 없다. 질의 최적화기(query optimizer)가 최적의 접근 경로를 만들어준다.
문서 모델과 계층 모델의 비교
문서 모델과 계층 모델의 공통점 - 별도 테이블이 아닌 상위 레코드 내에 중첩된 레코드(ex. 지역, 교육사항 등)를 저장한다.
문서 모델과 관계형 모델의 공통점 - 다대일과 다대다 관계 표현 시 관련 항목은 고유한 식별자로 참조한다. -> 관계형 모델 = 외래 키(foreign key) -> 문서 모델 = 문서 참조(document reference) - 조인이나 후속 질의를 사용해 읽기 시점에 확인 - 문서 모델은 코다실 모델의 전철을 밟고 있지 않음.
관계형 데이터베이스와 오늘날의 문서 데이터베이스
관계형 데이터베이스와 문서 데이터베이스의 차이 1. 내결함성(5장 참고), 동시성 처리(7장 참고) 2. 데이터 모델에서의 차이점 - 문서 데이터 모델: 스키마 유연성, 지역성(성능), 애플리케이션 데이터 구조와 가까움 - 관계 데이터 모델: 조인, 다대일, 다대다 관계 지원 높음
데이터 항목 관계 유형에 따라 어떤 모델이 나은 지 판단 필요
- 데이터가 문서와 비슷한 구조일 경우(일대다 구조) -> 문서 모델 사용 -> 여러 테이블로 나누어 찢는(shredding) 관계형 기법은 스키마와 복잡한 애플리케이션 코드 발생됨 - 정규화된 데이터(다대일, 다대다 관계 사용 구조) -> 관계 모델 사용 ··· 조인 강점 - 상호 연결이 많은 데이터 -> 그래프 모델(or 관계 모델) 사용
문서 모델에서의 스키마 유연성
스키마 강요 - JSON(문서형, 관계형): 스키마 강요 X - XML(관계형): 스키마 유효성 검사 포함 가능 ※ 스키마가 없다는 뜻은 임의의 키와 값을 문서에 추가할 수 있고 읽을 때 필드의 존재 여부를 보장하지 않는다는 의미
쓰기 스키마(schema-on-write): 관계형 DB의 접근 방식으로 스키마를 명시하고 DB는 스키마를 따른다.(정적) 읽기 스키마(schema-on-read): 데이터 구조는 암묵적이며 데이터를 읽을 때 해석한다.(동적)
질의를 위한 데이터 지역성
웹 상에 문서를 보여주는 동작처럼 애플리케이션이 자주 전체 문서에 접근 시 저장소 지역성(Storage location)을 활용하여 성능 향상 필요 부분이 작을 때 큰 문서를 접근하는 경우 낭비(문서 전체를 적재하기 때문) -> 문서를 작게 유지, 문서 크기 증가하는 쓰기 지양
지역성 특성을 가진 관계 DB - 구글, 스패너(Spanner) - 오라클, 다중 테이블 색인 클러스터 테이블(multi-table index cluster table)
관계형 데이터베이스와 문서 데이터베이스는 시간이 지남에 따라 서로 비슷해지고 있다.
데이터를 위한 질의 언어
관계형 모델이 등장하면서 데이터 질의 방법도 새로 등장
모델에 따른 질의언어 1. 선언형 질의언어 -> SQL, 관계대수 - 목표를 달성하기 위한 방법이 아닌 결과가 충족해야 하는 조건과 데이터를 어떻게 변환(정렬, 그룹화 등)할지 지정 - 명령을 실행할 때 접근 경로는 질의 최적화기(query optimizer)가 결정 - 명령형 언어보다 간결하게 작업할 수 있고 상세 구현이 숨겨져있어 질의를 변경하지 않고 성능 향상 가능 - 병렬 실행에 적합
2. 명령형 코드 질의언어 -> IMS(계층 모델), 코다실(네트워크 모델), 프로그래밍 언어 - 특정 순서로 특정 연산을 수행하도록 컴퓨터에게 지시 - ex) 한줄씩 단계별 실행하여 조건을 평가하고 변수를 갱신하고 루프를 더 실행할지 여부 결정
웹에서의 선언형 질의
선언형 질의의 장점은 데이터베이스에만 국한되지 않는다. -> 웹 CSS, XSL 명령형 접근방식은 JavaScript 코어 DOM(Document Object Model) API
맵리듀스 질의
맵리듀스(MapReduce)는 많은 컴퓨터에서 대량의 데이터를 처리하기 위한 프로그래밍 모델 map(collect)과 reduce(fold, inject) 함수를 기반으로 하며, 선언형 질의와 명령형 질의의 중간 정도 모델 몽고DB와 카우치DB 등 일부 NoSQL 데이터베이스에서 맵리듀스를 지원한다.
오늘날 대부분의 애플리케이션은 계산 중심(compute-intensive)이 아닌 데이터 중심적(data-intensive)이다.
많은 애플리케이션은 다음을 필요로 한다. - 데이터베이스: 구동 애플리케이션이나 다른 애플리케이션에서 나중에 다시 데이터를 찾을 수 있게 데이터 저장 - 캐시: 읽기 속도 향상을 위해 값비싼 수행 결과를 기억 - 검색 색인(search index): 사용자가 키워드로 데이터를 검색하거나 다양한 방법으로 필터링할 수 있도록 제공 - 스트림 처리: 비동기 처리를 위해 다른 프로세스로 메시지 보내기 - 일괄 처리(batch processing): 주기적으로 대량의 누적된 데이터 분석
데이터 시스템에 대한 생각
데이터베이스, 큐, 캐시 등을 데이터 시스템이라는 포괄적 용어로 묶는다. 첫번째 이유, 데이터 저장과 처리를 위한 새로운 도구는 최근에 만들어졌다. 새로운 도구는 다양한 사용 사례(use case)에 최적화되었기 때문에 전통적인 분류에 정확히 들어맞지 않는다. (ex. redis는 메시지 큐로 사용하는 데이터스토어, Apache Kafka는 DB처럼 지속성을 보장하는 메시지 큐) 두번째 이유, 단일 도구로는 데이터 처리와 저장을 모두 만족시킬 수 없는 과도하고 광범위한 요구사항을 갖고 있음.
대부분의 소프트웨어 시스템에서 중요하게 여기는 세 가지 관심사 1. 신뢰성(Reliability): 결함(fault)이 있더라도 시스템은 지속적으로 올바르게 동작 2. 확장성(Scalability): 시스템 데이터 양, 트래픽 양 복잡도가 증가하면서 이를 처리할 적절한 방법 존재 3. 유지보수성(Maintainability): 시간이 지나도 모든 사용자가 시스템 상에서 생산적으로 작업할 수 있어야 함.
신뢰성
"무엇인가 잘못되어도 지속적으로 올바르게 동작함." (대략적인 의미)
결함과 장애는 동일하지 않다. - 결함(fault): 잘못될 수 있는 일 -> 결함을 예측하고 대처할 수 있는 시스템을 결함성(fault-tolerant) 또는 탄력성(resilient)을 지녔다고 함. - 장애(faliure): 사용자에게 서비스를 제공하지 못하고 시스템 전체가 멈춤
1. 하드웨어 결함 가. 원인: 하드디스크 고장, 램 결함, 정전 등 나. 대응책: 디스크 RAID 구성, 서버 이중 전원 디바이스와 핫 스왑(hot-swap) 가능한 CPU설치, 예비 전원용 디젤 발전기 설치 -> 구성요소 하나가 죽으면 고장난 구성 요소가 교체되는 동안 중복된 구성 요소를 대신 사용할 수 있음.
2. 소프트웨어 오류 가. 원인: 시스템 내 체계적 오류(systematic error) 나. 특징: 예상하기 어렵고 노드 간 상관관계 때문에 상관관계없는 하드웨어 결함보다 오히려 시스템 오류를 더욱 많이 유발하는 경향 다. 해결책: 신속한 해결이 어렵다. 시스템에 가정과 상호작용에 대해 주의 깊게 생각하기, 빈틈없는 테스트, 프로세스 격리, 죽은 프로세스의 재시작 허용 등
3. 인적 오류 가. 원인: 운영자의 설정 오류 등 나. 방지책 - 오류의 가능성을 최소화하는 방향으로 시스템 설계(ex. 잘 설계된 추상화, API, 관리 인터페이스 사용) - 실제 데이터를 확인할 수 있지만 사용자에겐 영향이 없는 비 프로덕션 샌드박스(sandbox) 제공 - 단위 테스트부터 전체 시스템 통합 테스트와 수동 테스트까지 철저하게 테스트 - 장애 발생 영향을 최소화하기 위해 오류를 빠르고 쉽게 복구할 수 있도록 함 - 성능 지표와 오류율 같은 상세하고 명확한 모니터링 대책 마련 - 조작 교육과 실습 시행
확장성
증가한 부하에 대처하는 시스템의 능력을 설명(ex. "시스템이 특정 방식으로 커지면 이에 대처하기 위한 선택은 무엇인가 또 추가 부하를 다루기 위해 계산 자원을 어떻게 투입하는가")
1. 부하 기술하기
먼저 시스템의 현재 부하를 간결하게 기술한다.
부하는 부하 매개변수(load parameter)라 부르는 몇 개의 숫자로 나타낼 수 있다. -> ex. 웹 서버의 초당 요청 수, DB의 읽기 대 쓰기 비율, 대화방의 동시 활성 사용자, 캐시 적중률 등
2. 성능 기술하기
시스템 부하를 기술하면 부하가 증가할 때 어떤 일이 일어나는지 조사할 수 있다.
시스템 부하 기술 방법 - 부하 매개변수를 증가시키고 시스템 자원은 변경하지 않고 유지하면 시스템 성능은 어떻게 영향을 받는가? - 부하 매개변수를 증가시켰을 때 성능이 변하지 않고 유지되길 원한다면 자원을 얼마나 늘려야 하는가?
시스템 성능 측정에 필요한 수치 - 일괄 처리 시스템 -> 처리량(throughput): 초당 처리할 수 있는 레코드 수나 데이터 집합으로 작업을 수행할 때 걸리는 전체 시간) - 온라인 시스템 -> 응답 시간(response time): 클라이언트가 요청을 보내고 응답을 받는 사이의 시간
※ 지연 시간(latency)과 응답 시간(response time): 지연 시간과 응답 시간은 다름. - 응답 시간은 클라이언트 관점에서 본 시간(요청을 처리하는 실제 시간 + 네트워크 지연 시간 + 큐 지연시간) - 지연 시간은 요청이 처리되길 기다리는 시간(서비스를 기다리며 휴지(latent) 상태인 시간을 말함)
응답 시간은 동일한 요청에도 매번 응답 시간이 다르기 때문에 단일 숫자가 아니라 측정 가능한 값의 분포로 생각해야 한다.
서비스 평균 응답 시간을 살피는 것에 있어서 산술 평균을 사용하는 것보다 백분위를 사용하는 편이 더 좋다.
응답 시간의 목록을 가지고 가장 빠른 시간부터 제일 느린 시간까지 정렬하면 중간 지점이 중앙값이 된다. - 사용자 요청의 절반은 중앙값 응답 시간 미만으로 제공되고 나머지 반은 중앙값보다 오래 걸린다. 중앙값은 50분위로서 p50으로 축약 - 상위 백분위 응답시간(=꼬리 지연 시간(tail latency))으로 특이 값이 얼마나 좋지 않은지 파악할 수 있음(95p, 99p, 999p) -> 아마존은 99.9분위(999p) 사용 - 큐 대기 지연은 높은 백분위에서 소수의 느린 요청 처리만으로도 후속 요청 처리가 지체된다.(=선두 차단(head-of-line blocking)) -> 클라이언트 측 응답시간 측정이 중요하며, 응답 시간과 독립 적으로 요청을 계속 보내야 한다. 이전 요청 완료까지 기다리면 테스트에서 인위적으로 실제 대기 시간을 더 짧게 만들어 평가를 왜곡함.
3. 부하 대응 접근 방식
좋은 성능을 유지하는 방법
- 용량 확장(scailing up)(수직 확장(vertical scaling), 강력한 장비로 이동) - 규모 확장(scailing out)(수평 확장(horizontal scaling), 다수의 낮은 사양 장비에 부하를 분산)
부하 증가를 감지하면 컴퓨팅 자원을 자동으로 추가할 수 있음(탄력적(elastic) 시스템). 탄력적 시스템은 부하를 예측할 수 없을 때 유용하지만 수동으로 확장하는 시스템이 더 간단하고 운영상 예기치 못한 일이 적다.
단일 노드 상태유지(stateful) 데이터 시스템은 분산 설치는 복잡도가 높아 확장 비용이나 데이터베이스를 분산으로 만들어야 하는 고가용성 요구가 있을 때까지 단일 노드에 데이터베이스를 유지하는 것(용량 확장(scailing up)) -> 최근까지의 통념이었지만 분산 시스템을 위한 도구와 추상화가 좋아지면서 일부는 바뀌었음.
유지보수성
유지보수성을 위한 소프트웨어 시스템 설계 원칙 세 가지 1. 운용성: 운영의 편리함 만들기 -> 반복 task를 줄여 업무 생산성을 높임 - 모니터링 제공하여 런타임 동작과 시스템 내부 가시성 제공 - 표준 도구 이용하여 자동화와 통합을 위한 지원 - 개별 장비 의존성 회피 - 좋은 문서와 이해하기 쉬운 운영 모델 제공 - 기본값을 다시 정의할 수 있는 자유를 관리자에게 부여 - 예측 가능하게 하고 예기치 않은 상황 최소화
2. 단순성: 복잡도 관리 -> 복잡도를 줄여야 함 - 우발적 복잡도를 제거하기 위한 최상의 도구는 추상화다.(세부 구현을 숨길 수 있고 재사용성이 높음)
3. 발전성: 변화를 쉽게 만들기 - 요구사항은 끊임없이 변하기 때문 - 애자일 작업 패턴 적용
사내 교육 외부 초청 강사님으로 오신 구멍가게코딩단 강요천 강사님의 추천으로 책을 공부한다. 생소한 내용이 많아 어렵지만 정리를 하며 이해도를 높이고자 한다.
책을 완독하여 데이터베이스 분야를 전문적으로 공부할지 개발 공부를 더 할지 결정할 수 있는 계기가 되었으면 한다.
머리말
최근 10년간 데이터베이스와 분산 시스템 분야에서 발전이 있었고 이를 기반으로 Application을 개발하는 방법에도 발전이 있었다. 이런 발전의 원동력은 매우 다양하다.
- 엄청난 양의 데이터와 트래픽으로 생산으로 인하여 이를 효율적으로 처리하기 위해 새로운 도구를 만들어야 했다. - 기업은 민첩하고 작은 노력으로 가설을 테스트해야 한다. 이를 위해 개발 주기를 단축하고 데이터 모델을 유연하게 해야 한다. - CPU 클럭 속도는 거의 증가하지 않고 있다. 병렬 처리의 사용 필요성이 늘어나고 있다. - 사람들은 많은 서비스에 고가용성을 요구한다. 서비스 중단을 원하지 않는다.
데이터 중심 애플리케이션(data-intensive application)은 이러한 기술적 발전을 활용해 실현 가능 범위를 넓힌다.
데이터 중심적(data-intensive)란 데이터 양, 데이터 복잡성, 데이터가 변하는 속도 등 데이터가 주요 도전 과제인 애플리케이션 계산 중심적(compute-intensive)란 CPU사이클이 병목인 경우의 애플리케이션
책의 목적 - 다양하고 빠르게 변하는 데이터 저장과 처리 기술 분야를 배움 - 데이터 시스템의 내부를 보고 핵심 알고리즘을 파악하고 그 원리와 알고리즘이 가진 트레이드오프를 설명함 - 특정 목적에 어떤 기술이 적합한지 결정하는 방법과 애플리케이션 아키텍처의 기반을 만들기 위해 도구를 조합하는 방법 설명
Annotation(@)은 사전적 의미로는 주석이라는 뜻이다. 자바에서Annotation은 코드 사이에 주석처럼 쓰이며 특별한 의미, 기능을 수행하도록 하는 기술이다. 즉, 프로그램에게 추가적인 정보를 제공해주는 메타데이터라고 볼 수 있다. meta data: 데이터를 위한 데이터)
다음은어노테이션의 용도를 나타낸 것이다.
컴파일러에게 코드 작성 문법 에러를 체크하도록 정보를 제공한다.
소프트웨어 개발 툴이빌드나 배치시 코드를 자동으로 생성할 수 있도록 정보를 제공한다.
실행시(런타임시)특정 기능을 실행하도록 정보를 제공한다.
기본적으로 어노테이션을 사용하는 순서는 다음과 같다.
어노테이션을 정의한다.
클래스에 어노테이션을 배치한다.
코드가 실행되는 중에Reflection을 이용하여 추가 정보를 획득하여 기능을 실시한다.
Reflection 이란?
Reflection이란프로그램이 실행 중에 자신의 구조와 동작을 검사하고, 조사하고, 수정하는 것이다.
Reflection은 프로그래머가데이터를 보여주고, 다른 포맷의 데이터를 처리하고, 통신을 위해 serialization(직렬화)를 수행하고,bundling을 하기 위해 일반 소프트웨어 라이브러리를 만들도록 도와준다.
Java와 같은 객체 지향 프로그래밍 언어에서Reflection을 사용하면 컴파일 타임에 인터페이스, 필드, 메소드의 이름을 알지 못해도 실행 중에 클래스, 인터페이스, 필드 및 메소드에 접근할 수 있다.
또한새로운 객체의 인스턴스화 및 메소드 호출을 허용한다.
Java와 같은 객체 지향 프로그래밍 언어에서Reflection을 사용하여 멤버 접근 가능성 규칙을 무시할 수 있다. [EX] reflection을 사용하면 서드 파티 라이브러리의 클래스에서 private 필드의 값을 변경할 수 있다.
Spring에서 BeanFactory라는 Container에서 객체가 호출되면 객체의 인스턴스를 생성하게 되는데 이 때 필요하게 된다. 즉, 프레임워크에서 유연성있는 동작을 위해 쓰인다.
Annotation자체는 아무런 동작을 가지지 않는 단순한 표식일 뿐이지만,Reflection을 이용하면Annotation의 적용 여부와 엘리먼트 값을 읽고 처리할 수 있다.
Class에 적용된Annotation정보를 읽으려면 java.lang.Class를 이용하고 필드, 생성자, 메소드에 적용된 어노테이션 정보를 읽으려면 Class의 메소드를 통해 java.lang.reflect 패키지의 배열을 얻어야 한다.
Class.forName(), getName(), getModifier(), getFields() getPackage() 등등 여러 메소드로 정보를 얻을 수 있다.
Reflection을 이용하면Annotation지정만으로도 원하는 클래스를 주입할 수 있다.
// Without reflection
Foo foo = new Foo();
foo.hello();
// With reflection
Object foo = Class.forName("complete.classpath.and.Foo").newInstance();
// Alternatively: Object foo = Foo.class.newInstance();
Method m = foo.getClass().getDeclaredMethod("hello", **new** Class<?>[0]);
m.invoke(foo);
Annotation 종류
@ComponentScan
@Component와 @Service, @Repository, @Controller, @Configuration이 붙은 클래스 Bean들을 찾아서 Context에 bean등록을 해주는 Annotation이다. @Component Annotation이 있는 클래스에 대하여 bean 인스턴스를 생성
ApplicationContext.xml에<bean id="jeongpro" class="jeongpro" />과 같이 xml에 bean을 직접등록하는 방법도 있고 위와 같이Annotation을 붙여서 하는 방법도 있다.
base-package를 넣으면 해당 패키지 아래에 있는 컴포넌트들을 찾고 그 과정을 spring-context-버전(4.3.11.RELEASE).jar에서 처리한다.
Spring에서@Component로 다 쓰지 않고 @Repository, @Service, @Controller등을 사용하는 이유는, 예를들어@Repository는 DAO의 메소드에서 발생할 수 있는 unchecked exception들을 스프링의 DataAccessException으로 처리할 수 있기 때문이다.
또한 가독성에서도 해당 애노테이션을 갖는 클래스가 무엇을 하는지 단 번에 알 수 있다.
자동으로 등록되는 Bean의 이름은 클래스의 첫문자가 소문자로 바뀐 이름이 자동적용된다. HomeController -> homeController
@Component
@Component은개발자가 직접 작성한 Class를 Bean으로 등록하기 위한 Annotation이다.
@Component
public class Student {
public Student() {
System.out.println("hi");
}
}
@Component(value="mystudent")
public class Student {
public Student() {
System.out.println("hi");
}
}
Component에 대한추가 정보가 없다면Class의 이름을 camelCase로 변경한 것이 Bean id로 사용된다.
하지만@Bean과 다르게@Component는 name이 아닌 value를 이용해 Bean의 이름을 지정한다.
@Bean
@Bean은개발자가 직접 제어가 불가능한 외부 라이브러리등을 Bean으로 만들려할 때 사용되는 Annotation이다.
@Configuration
public class ApplicationConfig {
@Bean
public ArrayList<String> array(){
return new ArrayList<String>();
}
}
ArrayList같은라이브러리등을 Bean으로 등록하기 위해서는 별도로해당 라이브러리 객체를 반환하는 Method를 만들고@BeanAnnotation을 사용하면 된다.
위의 경우@Bean에 아무런 값을 지정하지 않았으므로 Method 이름을 camelCase로 변경한 것이 Bean id로 등록된다. method 이름이 arrayList()인 경우 arrayList가 Bean id
@Configuration
public class ApplicationConfig {
@Bean(name="myarray")
public ArrayList<String> array(){
return new ArrayList<String>();
}
}
위와 같이@Bean에 name이라는 값을 이용하면 자신이 원하는 id로 Bean을 등록할 수 있다.
@Autowired
속성(field), setter method, constructor(생성자)에서 사용하며Type에 따라 알아서 Bean을 주입 해준다. 무조건적인 객체에 대한 의존성을 주입시킨다. 이Annotation을 사용할 시, 스프링이 자동적으로 값을 할당한다. Controller 클래스에서 DAO나 Service에 관한 객체들을 주입 시킬 때 많이 사용한다.
필드, 생성자, 입력 파라미터가 여러 개인 메소드(@Qualifier는 메소드의 파라미터)에 적용 가능하다.
Type을 먼저 확인한 후 못 찾으면 Name에 따라 주입한다. Name으로 강제하는 방법: @Qualifier을 같이 명시
Bean을 주입받는 방식 (3가지)
@Autowired
setter
생성자 (@AllArgsConstructor 사용) -> 권장방식
@Inject
@Autowired어노테이션과 비슷한 역할을 한다.
@Controller
Spring의 Controller를 의미한다. Spring MVC에서 Controller클래스에 쓰인다.
@RestController
Spring에서 Controller 중 View로 응답하지 않는, Controller를 의미한다.
method의 반환 결과를 JSON 형태로 반환한다.
이 Annotation이 적혀있는 Controller의 method는 HttpResponse로 바로 응답이 가능하다. @ResponseBody 역할을 자동적으로 해주는 Annotation이다. @Controller + @ResponseBody를 사용하면 @ResponseBody를 모든 메소드에서 적용한다.
@Controller 와 @RestController 의 차이
@Controller API와 view를 동시에 사용하는 경우에 사용한다. 대신 API 서비스로 사용하는 경우는 @ResponseBody를 사용하여 객체를 반환한다. view(화면) return이 주목적이다.
@RestController view가 필요없는 API만 지원하는 서비스에서 사용한다. Spring 4.0.1부터 제공 @RequestMapping 메서드가 기본적으로 @ResponseBody 의미를 가정한다. data(json, xml 등) return이 주목적이다.
즉, @RestController = @Controller + @ResponseBody 이다.
@Service
Service Class에서 쓰인다. 비즈니스 로직을 수행하는 Class라는 것을 나타내는 용도이다.
@Repository
DAO class에서 쓰인다. DataBase에 접근하는 method를 가지고 있는 Class에서 쓰인다.
@EnableAutoConfiguration
Spring Application Context를 만들 때 자동으로 설정하는 기능을 켠다.
classpath의 내용에 기반해서 자동으로 생성해준다.
만약tomcat-embed-core.jar가 존재하면 톰캣 서버가 setting된다.
@Configuration
@Configuration을 클래스에 적용하고@Bean을 해당 Class의 method에 적용하면 @Autowired로 Bean을 부를 수 있다.
@Required
setter method에 적용해주면 Bean 생성시 필수 프로퍼티 임을 알린다.
Required Annotation을 사용하여 optional 하지 않은, 꼭 필요한 속성들을 정의한다.
영향을 받는 bean property를 구성할 시에는XML 설정 파일에 반드시 property를 채워야 한다. 엄격한 체크, 그렇지 않으면 BeanInitializationException 예외를 발생
<!-- Definition for student bean -->
<bean id = "student" class = "com.tutorialspoint.Student">
<property name = "name" value = "Zara" />
<property name = "age" value = "11"/>
</bean>
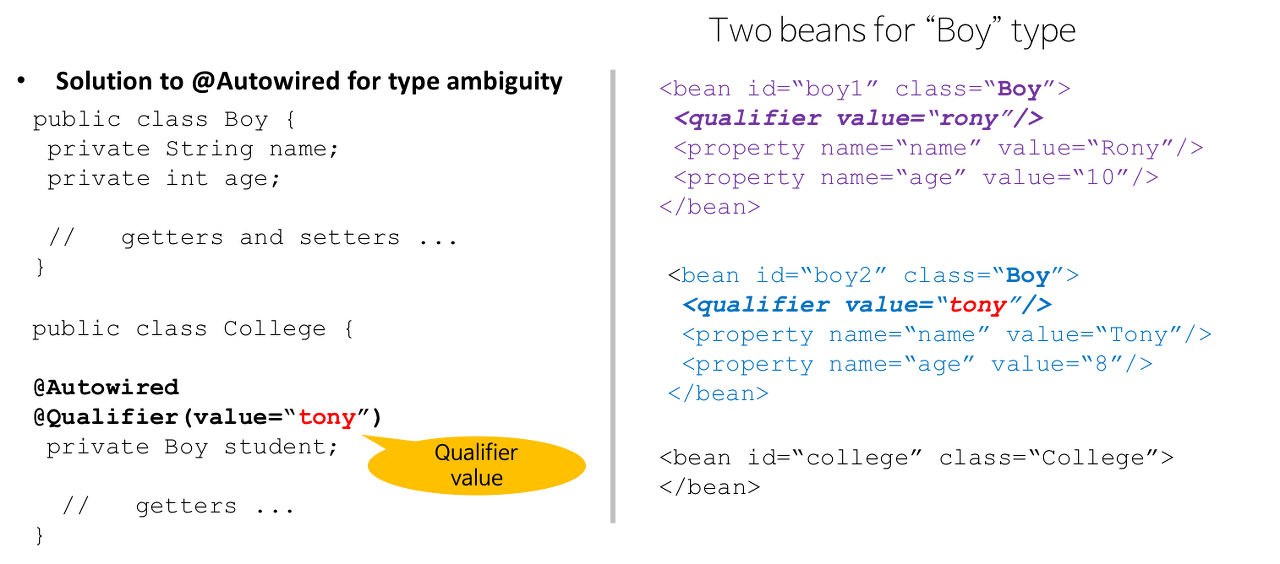
@Qualifier("id123")
@Autowired와 같이 쓰이며,같은 타입의 Bean 객체가 있을 때 해당 아이디를 적어 원하는 Bean이 주입될 수 있도록 하는 Annotation이다. 같은 타입이 존재하는 경우 ex) 동물 = 원숭이, 닭, 개, 돼지
같은 타입의 Bean이 두 개 이상이 존재하는 경우에Spring이 어떤 Bean을 주입해야 할지 알 수 없어서 Spring Container를 초기화하는 과정에서 예외를 발생시킨다.
이 경우 @Qualifier을 @Autowired와 함께 사용하여정확히 어떤 bean을 사용할지 지정하여 특정 의존 객체를 주입할 수 있도록 한다.
예시
xml 설정에서 bean의 한정자 값(qualifier value)을 설정한다. @Autowired 어노테이션이 적용된 주입 대상에 @Qualifier 어노테이션을 설정한다.
@Resource
@Autowired와 마찬가지로 Bean 객체를 주입해주는데차이점은 Autowired는 타입으로, Resource는 이름으로 연결해준다.
javax.annotation.Resource 표준 자바(JSR-250 표준) Annotation으로, Spring Framework 2.5.* 부터 지원 가능한 Annotation이다.
Annotation 사용으로 인해 특정 Framework에 종속적인 어플리케이션을 구성하지 않기 위해서는 @Resource를 사용할 것을 권장한다.
@Resource를 사용하기 위해서는 class path 내에 jsr250-api.jar 파일을 추가해야 한다. 필드, 입력 파라미터가 한 개인 bean property setter method에 적용 가능하다.
@PostConstruct, @PreConstruct
의존하는 객체를 생성한 이후 초기화 작업을 위해 객체 생성 전/후에(pre/post) 실행해야 할 method 앞에 붙인다.
@PreDestroy
객체를 제거하기 전(pre)에 해야할 작업을 수행하기 위해 사용한다.
@PropertySource
해당 프로퍼티 파일을 Environment로 로딩하게 해준다.
클래스에 @PropertySource("classpath:/settings.properties")라고 적고 클래스 내부에 @Resource를 Environment타입의 멤버 변수앞에 적으면 매핑된다.
@Controller
// 1) Class Level
//모든 메서드에 적용되는 경우 “/home”로 들어오는 모든 요청에 대한 처리를 해당 클래스에서 한다는 것을 의미
@RequestMapping("/home")
public class HomeController {
/* an HTTP GET for /home */
@RequestMapping(method = RequestMethod.GET)
public String getAllEmployees(Model model) {
...
}
/*
2) Handler Level
요청 url에 대해 해당 메서드에서 처리해야 되는 경우
“/home/employees” POST 요청에 대한 처리를 addEmployee()에서 한다는 것을 의미한다.
value: 해당 url로 요청이 들어오면 이 메서드가 수행된다.
method: 요청 method를 명시한다. 없으면 모든 http method 형식에 대해 수행된다.
*/
/* an HTTP POST for /home/employees */
@RequestMapping(value = "/employees", method = RequestMethod.POST)
public String addEmployee(Employee employee) {
...
}
}
@RequestMapping에 대한 모든 매핑 정보는 Spring에서 제공하는 HandlerMapping Class가 가지고 있다.
@CookieValue
쿠키 값을 parameter로 전달 받을 수 있는 방법이다.
해당 쿠키가 존재하지 않으면 500 에러를 발생시킨다.
속성으로 required가 있는데 default는 true다. false를 적용하면 해당 쿠키 값이 없을 때 null로 받고 에러를 발생시키지 않는다.
// 쿠키의 key가 auth에 해당하는 값을 가져옴
public String view(@CookieValue(value="auth")String auth){...};
@CrossOrigin
CORS 보안상의 문제로 브라우저에서 리소스를 현재origin에서 다른 곳으로의 AJAX요청을 방지하는 것이다.
@RequestMapping이 있는 곳에 사용하면 해당 요청은 타 도메인에서 온 ajax요청을 처리해준다.
//기본 도메인이 http://jeong-pro.tistory.com 인 곳에서 온 ajax요청만 받아주겠다.
@CrossOrigin(origins = "http://jeong-pro.tistory.com", maxAge = 3600)
@ModelAttribute
view에서 전달해주는 parameter를 Class(VO/DTO)의 멤버 변수로 binding 해주는 Annotation이다.
binding 기준은<input name="id" />처럼어떤 태그의 name값이 해당 Class의 멤버 변수명과 일치해야하고 setmethod명도 일치해야한다.
class Person{
String id;
public void setId(String id){ this.id = id;}
public String getId(){ return this.id }
}
@Controller
@RequestMapping("/person/*")
public class PersonController{
@RequestMapping(value = "/info", method=RequestMethod.GET)
//view에서 myMEM으로 던져준 데이터에 담긴 id 변수를 Person타입의 person이라는 객체명으로 바인딩.
public void show(@ModelAttribute("myMEM") Person person, Model model)
{ model.addAttribute(service.read(person.getId())); }
}
@GetMapping
@RequestMapping(Method=RequestMethod.GET)과 같다. @PostMapping, @PutMapping, @PatchMapping, @DeleteMapping 등 도 있다.
@SessionAttributes
Session에 data를 넣을 때 쓰는 Annotation이다.
@SessionAttributes("name")이라고 하면 Model에 key값이 "name"으로 있는 값은 자동으로 세션에도 저장되게 한다.
@Valid
유효성 검증이 필요한 객체임을 지정한다.
@InitBinder
@Valid 애노테이션으로 유효성 검증이 필요하다고 한 객체를 가져오기전에 수행해야할 method를 지정한다.
@RequestAttribute
Request에 설정되어 있는 속성 값을 가져올 수 있다.
@RequestBody
요청이 온 데이터(JSON이나 XML형식)를 바로 Class나 model로 매핑하기 위한 Annotation이다.
POST나 PUT, PATCH로 요청을 받을때에,요청에서 넘어온 body 값들을 자바 타입으로 파싱해준다.
HTTP POST 요청에 대해 request body에 있는 request message에서 값을 얻어와 매핑한다. RequestData를 바로 Model이나 클래스로 매핑한다.
이를테면JSON 이나 XML같은 데이터를 적절한 messageConverter로 읽을 때 사용하거나 POJO 형태의 데이터 전체로 받는 경우에 사용한다.
@RequestMapping(value = "/book", method = RequestMethod.POST)
public ResponseEntity<?> someMethod(@RequestBody Book book) {
// we can use the variable named book which has Book model type.
try {
service.insertBook(book);
} catch(Exception e) {
e.printStackTrace();
}
// return some response here
}
@RequestHeader
Request의 header값을 가져올 수 있다. 메소드의 파라미터에 사용한다.
//ko-KR,ko;q=0.8,en-US;q=0.6
@RequestHeader(value="Accept-Language")String acceptLanguage 로 사용
@RequestParam
@PathVariable과 비슷하다. request의 parameter에서 가져오는 것이다.method의 파라미터에 사용된다. ?moviename=thepurge 와 같은 쿼리 파라미터를 파싱해준다.
HTTP GET 요청에 대해 매칭되는 request parameter 값이 자동으로 들어간다. url 뒤에 붙는 parameter 값을 가져올 때 사용한다.
http://localhost:8080/home?index=1&page=2
@GetMapping("/home")
public String show(@RequestParam("page") int pageNum {
}
위의 경우 GET /home?index=1&page=2와 같이 uri가 전달될 때 page parameter를 받아온다. @RequestParam 어노테이션의 괄호 안의 문자열이 전달 인자 이름(실제 값을 표시)이다.
@RequestMapping(value = "/search/movie", method = RequestMethod.GET)
public ResponseEntity<?> someMethod(@RequestParam String moviename) {
// request URI would be like '/search/movie?moviename=thepurge'
try {
List<Movie> movies = service.searchByMoviename(moviename);
} catch(Exception e) {
e.printStackTrace();
}
// return some response here
}
@RequestPart
Request로 온 MultipartFile을 바인딩해준다.
@RequestPart("file") MultipartFile file
@ResponseBody
HttpMessageConverter를 이용하여 JSON 혹은 xml 로 요청에 응답할수 있게 해주는 Annotation이다. view가 아닌 JSON 형식의 값을 응답할 때 사용하는 Annotation으로문자열을 리턴하면 그 값을 http response header가 아닌 response body에 들어간다.
이미RestController Annotation이 붙어 있다면, 쓸 필요가 없다. 허나 그렇지 않은 단순 컨트롤러라면,HttpResponse로 응답 할 수 있게 해준다.
만약객체를 return하는 경우 JACKSON 라이브러리에 의해 문자열로 변환되어 전송된다.
context에 설정된 viewResolver를 무시한다고 보면된다.
@PathVariable
method parameter 앞에 사용하면서 해당 URL에서 {특정값}을 변수로 받아 올 수 있다.
@RequestMapping(value = "/some/path/{id}", method = RequestMethod.GET)
public ResponseEntity<?> someMethod(@PathVariable int id) {
}
HTTP 요청에 대해 매핑되는 request parameter 값이 자동으로 Binding 된다.
uri에서 각 구분자에 들어오는 값을 처리해야 할 때 사용한다.
REST API에서 값을 호출할 때 주로 많이 사용한다.
http://localhost:8080/index/1
@PostMapping("/index/{idx}")
@ResponseBody
public boolean deletePost(@PathVariable("idx") int postNum) {
return postService.deletePost(postNum);
}
@RequestParam와 @PathVariable 동시 사용 예제
@GetMapping("/user/{userId}/invoices")
public List<Invoice> listUsersInvoices(@PathVariable("userId") int user,
@RequestParam(value = "date", required = false) Date dateOrNull) {
}
위의 경우GET /user/{userId}/invoices?date=190101와 같이 uri가 전달될 때 구분자{userId}는@PathVariable(“userId”)로, 뒤에 이어붙은parameter는@RequestParam(“date”)로 받아온다.
@ExceptionHandler(ExceptionClassName.class)
해당 클래스의 예외를 캐치하여 처리한다.
@ControllerAdvice
Class 위에 ControllerAdvice를 붙이고어떤 예외를 잡아낼 것인지는 각 메소드 상단에 @ExceptionHandler(예외클래스명.class)를 붙여서 기술한다.
@RestControllerAdvice
@ControllerAdvice + @ResponseBody다.
@ResponseStatus
사용자에게 원하는 response code와 reason을 return해주는 Annotation이다.
@ResponseStatus(value = HttpStatus.NOT_FOUND, reason = "my page URL changed..") => 예외처리 함수 앞에 사용한다.
@EnableEurekaServer
Eureka 서버로 만들어준다.
@EnableDiscoveryClient
Eureka 서버에서 관리될 수 있는 클라이언트 임을 알려주기위한 Annotation이다.
@Transactional
데이터베이스 트랜잭션을 설정하고 싶은 method에 Annotation을 적용하면method 내부에서 일어나는 데이터베이스 로직이전부 성공하게되거나 데이터베이스 접근중 하나라도 실패하면 다시 롤백할 수 있게 해주는 Annotation이다.
@Transaction(readOnly=true, rollbackFor=Exception.class)에서 readOnly는 읽기전용임을 알리고 rollbackFor는 해당 Exception이 생기면 롤백하라는 뜻이다.
@Transaction(noRollbackFor=Exception.class)는 해당 Exception이 나타나도 롤백하지 말라는 뜻이다.
@Transaction(timeout = 10)은 10초안에 해당 로직을 수행하지 못하면 롤백하라는 뜻이다.
메소드 내에서 Exception이 발생하면 해당 메소드에서 이루어진 모든 DB 작업을 초기화한다. save 메소드를 통해서 10개를 등록해야 하는데 5번째에서 Exception이 발생하면 앞에 저장된 4개 까지 모두 롤백
정확히 얘기하면,이미 넣은걸 롤백시키는건 아니며, 모든 처리가 정상적으로 됐을때만 DB에 커밋하며 그렇지 않은 경우엔 커밋하지 않는 것이다.
비지니스 로직과 트랜잭션 관리는 대부분 Service에서 관리한다.
따라서 일반적으로 DB 데이터를 등록/수정/삭제 하는 Service 메소드는 @Transactional를 필수적으로 가져간다.
@Cacheable
method 앞에 지정하면해당 method를 최초에 호출하면 캐시에 적재하고 다음부터는 동일한 method 호출이 있을 때 캐시에서 결과를 가져와서 return하므로 method 호출 횟수를 줄여주는 Annotation이다.
주의할 점은입력이 같으면 항상 출력이 같은 method(=순수 함수)에 적용해야한다.
그런데 또 항상 같은 값만 뱉어주는 메서드에 적용하려면 조금 아쉬울 수 있다.
따라서 메서드 호출에 사용되는 자원이 많고 자주 변경되지 않을 때 사용하고 나중에 수정되면 캐시를 없애는 방법을 선택할 수 있다.
기본생성자의 접근 권한을 protected로 제한한다. 생성자로 protected Posts() {}와 같은 효과
Entity Class를 프로젝트 코드상에서 기본생성자로 생성하는 것은 금지하고,JPA에서 Entity 클래스를 생성하는것은 허용하기 위해 추가한다.
@AllArgsConstructor
모든 필드 값을 파라미터로 받는 생성자를 추가한다.
@RequiredArgsConstructor
final이나 @NonNull인 필드 값만 파라미터로 받는 생성자를 추가한다. final: 값이 할당되면 더 이상 변경할 수 없다.
@Getter
Class 내 모든 필드의 Getter method를 자동 생성한다.
@Setter
Class 내 모든 필드의 Setter method를 자동 생성한다.
Controller에서 @RequestBody로 외부에서 데이터를 받는 경우엔 기본생성자 + set method를 통해서만 값이 할당된다. 그래서 이때만 setter를 허용한다. Entity Class에는 Setter를 설정하면 안된다. 차라리 DTO 클래스를 생성해서 DTO 타입으로 받도록 하자
@ToString
Class 내 모든 필드의 toString method를 자동 생성한다.
@ToString(exclude = "password") 특정 필드를 toString() 결과에서 제외한다. 클래스명(필드1이름=필드1값, 필드2이름=필드2값, …) 식으로 출력된다.
@EqualsAndHashCode
equals와 hashCode method를 오버라이딩 해주는 Annotation이다.
@EqualsAndHashCode(callSuper = true)
callSuper 속성을 통해equals와 hashCode 메소드 자동 생성 시부모 클래스의 필드까지 감안할지 안 할지에 대해서 설정할 수 있다.
즉, callSuper = true로 설정하면 부모 클래스 필드 값들도 동일한지 체크하며, callSuper = false로 설정(기본값)하면 자신 클래스의 필드 값들만 고려한다.
@Builder
어느 필드에 어떤 값을 채워야 할지 명확하게 정하여 생성 시점에 값을 채워준다.
Constructor와 Builder의 차이
생성 시점에 값을 채워주는 역할은 똑같다. 하지만 Builder를 사용하면어느 필드에 어떤 값을 채워야 할지 명확하게 인지할 수 있다. 해당 Class의 Builder 패턴 Class를 생성 후 생성자 상단에 선언 시 생성자에 포함된 필드만 빌더에 포함된다.
@Data
@Getter@Setter@EqualsAndHashCode@AllArgsConstructor을 포함한 Lombok에서 제공하는 필드와 관련된 모든 코드를 생성한다.
실제로 사용하지 않는것이 좋다. 전체적인 모든 기능 허용으로 위험 존재
JPA Annotation
JPA를 사용하면 DB 데이터에 작업할 경우 실제 쿼리를 사용하지 않고 Entity 클래스의 수정을 통해 작업한다.
@Entity
실제 DB의 테이블과 매칭될 Class임을 명시한다. 즉, 테이블과 링크될 클래스임을 나타낸다.
Entity Class
가장 Core한 클래스로 클래스 이름을 언더스코어 네이밍(_)으로 테이블 이름을 매칭한다. SalesManage스.java -> sales_manager table
Controller에서 쓸 DTO 클래스란??
Request와 Response용 DTO는View를 위한 클래스로, 자주 변경이 필요한 클래스이다. Entity 클래스와 DTO 클래스를 분리하는 이유는View Layer와DB Layer를 철저하게 역할 분리하기 위해서다.
테이블과 매핑되는 Entity 클래스가 변경되면 여러 클래스에 영향을 끼치게 되는 반면 View와 통신하는 DTO 클래스(Request/ Response 클래스)는 자주 변경되므로 분리해야 한다.
@Table
Entity Class에 매핑할 테이블 정보를 알려준다. @Table(name = "USER") Annotation을 생략하면 Class 이름을 테이블 이름 정보로 매핑한다.
@Id
해당 테이블의PK 필드를 나타낸다.
@GeneratedValue
PK의 생성 규칙을 나타낸다. 가능한 Entity의 PK는 Long 타입의 Auto_increment를 추천 스프링 부트 2.0에선 옵션을 추가하셔야만 auto_increment가 된다.
기본값은 AUTO로, MySQL의 auto_increment와 같이 자동 증가하는 정수형 값이 된다.
@Column
테이블의 컬럼을 나타내며, 굳이선언하지 않더라도 해당 Class의 필드는 모두 컬럼이 된다. @Column을 생략하면 필드명을 사용해서 컬럼명과 매핑
@Column(name = "username") @Column을 사용하는 이유는,기본값 외에 추가로 변경이 필요한 옵션이 있을 경우 사용한다.
문자열의 경우 VARCHAR(255)가 기본값인데, 사이즈를 500으로 늘리고 싶거나(ex: title), 타입을 TEXT로 변경하고 싶거나(ex: content) 등의 경우에 사용